Within ULM-4, Filip Ilievski and Minh Lê investigate a new model of natural-language-processing (NLP). ULM-4 consists of two sub projects carried out by two PhD candidates. Filip Ilievski works on defining context and background knowledge while Minh Lê investigates NLP architectures for background knowledge integration.
Contemporary NLP does not put enough emphasis on background knowledge as systems are mostly driven by linguistic experience acquired through supervised learning. While such approaches work fine for well-known world objects (people, companies) and neutral situations, they fail to capture the context needed to resolve the inherent ambiguity of human language for unpopular objects. We aim to address this through NLP models that perform deeper language processing, and use background knowledge to shape the interpretation and influence every processing step.
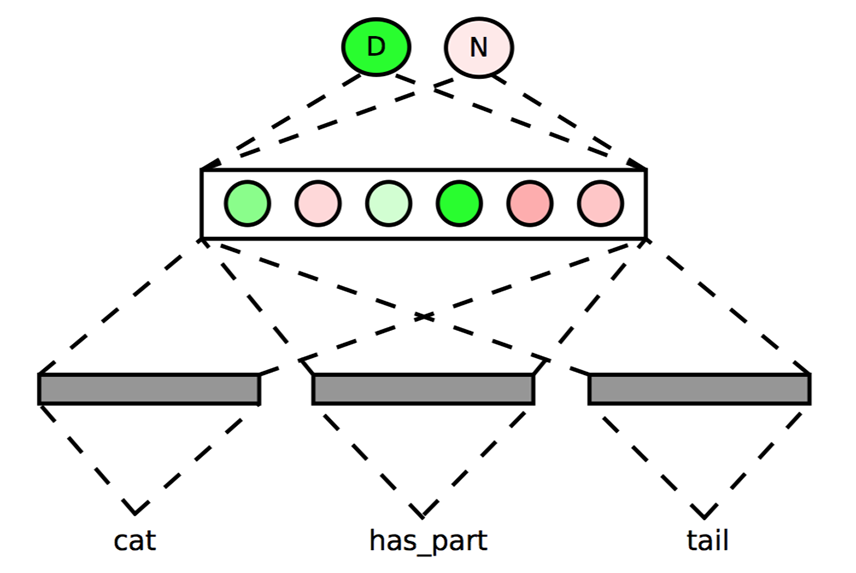 Figure: Forward propagation for an example: (cat, has_part, tail). Minh Lê’s presentation Dec. 10 2014: “Joint neural embeddings of synsets and entities.”
Figure: Forward propagation for an example: (cat, has_part, tail). Minh Lê’s presentation Dec. 10 2014: “Joint neural embeddings of synsets and entities.”
NLP Wheel
Current approaches are based on a pipeline architecture, in which the complete problem is divided in a series of smaller isolated tasks, e.g. tokenization, part-of-speech-tagging, lemmatization, syntactic parsing, recognition of entities, detection of word meanings. The process is essentially one-directional because a higher-level task has no influence on a lower-level one. The new model will execute in a circular manner, from low-level, lexical tasks to high-level, interpretative ones and back again.
Minh Lê is responsible for the development of this new approach. He works on syntactic parsing, (implicit) semantic role labeling, (event/entity) coreference resolution and the integration of those modules. He also develops the necessary training algorithm and data to train the system. The work will be done in collaboration with Ivan Titov from UvA.
Ultimately, this new approach should better mimic human language processing. Neurolinguistics has long established that humans actively make use of world knowledge during language processing. A change in brain electrical potential, called N400 effect, is found when a subject reads a semantically inconsistent word in the middle or at the end of a sentence. This signals an integrative process in which the brain tries to fit the latest word into a developing discourse.
Resources
1. Reproduction in Torch/Lua of Stanford experiment on neural network dependency parsing
2. Improved word2vec
Selected publications
- Minh Le and Antske Fokkens. Tackling Error Propagation through Reinforcement Learning: A Case of Greedy Dependency Parsing EACL, Valencia, 3-7 April 2017.
- Minh Le and Antske Fokkens. Taxonomy beats corpus in similarity identification, but does it matter? RANLP 2015.
- Tommaso Caselli, Piek Vossen, Marieke van Erp, Antske Fokkens, Filip Ilievski, Ruben Izquierdo Bevia, Minh Le, Roser Morante, and Marten Postma. When it’s all piling up: investigating error propagation in an NLP pipeline. In: Proceedings of the Workshop NLP Applications: completing the puzzle. WNACP 2015.
Language interpretation in long-tail, small-data contexts
Filip Ilievski deals with language interpretation that concerns specific, less popular situations called long-tail contexts. The goal of this PhD project is to build models that can make use of contextual clues and Semantic Web knowledge, and to formally define the optimal data that evaluates language interpretation within context. Building models that work for microcontexts is motivated by the fact that machines can deal with well-known world instances and concepts, because their statistical and probabilistic models are suitable for this. But how to teach them to process text in local contexts, for instance, a conversation between two friends on a terrace in Beirut, 50 years ago about the last night’s concert? This is an open and tough challenge. Filip’s work deals with various pieces of such long-tail NLP puzzle:
1. Which (Semantic Web) knowledge to provide to our machines, how to represent it, and how to infer (hidden) higher-level information and expectations from it? A Semantic Web-driven research on this topic has been done in collaboration with Wouter Beek, Marieke van Erp, Laurens Rietveld, and Stefan Schlobach. Currently, Filip is performing a research visit at the Carnegie Mellon University, under supervision of Prof. Dr. Ed Hovy. The topic of this visit is the hunger for knowledge in semantic NLP systems and generating expectations and stereotypes based on world knowledge.
2. Which data is suitable for evaluating the success of an NLP disambiguation system? How to define a tough enough use case that deals with the long tail of the world? There is a strong implicit connection between the type of data we use to assess the success of an NLP disambiguation system, and its strengths and weaknesses. Complex, context-aware NLP solutions need to be challenged and tested on test data exhibiting enough complexity. This is a research line which Filip pursues together with Marten Postma (Spinoza ULM-1) and Piek Vossen.
3. How to build effective models and intelligent systems that can switch between contexts and perform well on ambiguous and small-data problems? Filip is looking into contextual models and algorithms for the tasks of Entity Linking and Question Answering that can make an effective use of scarce knowledge. The work on this topics so far is a collaboration with Piek Vossen, Marieke van Erp, researchers from Eurecom (France) and ISMB (Italy).
Organizing
Recently, Filip was part of the organization team of the 2nd Spinoza Workshop: “Looking at the Long Tail”, where the participants discussed how to create a disambiguation task that evaluates correctly, and incentives good system performance on the long tail. Currently, Filip is organizing a global version of this workshop, entitled Semantics of the Long Tail, accepted at IJCNLP2017. At the same time, Filip organizes a SemEval-2018 task on a related topic of referential quantification in the long tail, together with Marten Postma (ULM-1) and Piek Vossen.
Selected publications
- Filip Ilievski, Wouter Beek, Marieke van Erp, Laurens Rietveld, Stefan Schlobach (2016). LOTUS: Adaptive Text Search for Big Linked Data. In proceedings of The Extended Semantic Web Conference (EWSC). Crete, Greece.
- Filip Ilievski, Marten Postma, Piek Vossen (2016). Semantic overfitting: what ‘world’ do we consider when evaluating disambiguation of text?. In proceedings of COLING 2016. Osaka, Japan.
- Marieke van Erp, Pablo Mendes, Heiko Paulheim, Filip Ilievski, Julien Plu, Giuseppe Rizzo and Joerg Waitelonis (2016). Evaluating Entity Linking: An Analysis of Current Benchmark Datasets and a Roadmap for Doing a Better Job. In proceedings of LREC 2016. Portoroz, Slovenia.
- Filip Ilievski, Piek Vossen, Marieke van Erp (2017). Hunger for Contextual Knowledge and a Road Map to Intelligent Entity Linking. In The International Conference on Language, Data and Knowledge (LDK). Galway, Ireland.